
“Continuous Delivery” is a concept in software development where updates to IT products are promoted to production on a rapid cadence. Each organisation and industry is different, but delivering changes at least once a day is a commonly accepted definition.
While there are obvious risks to releasing code at such a frequency, continuous delivery enables a host of business capabilities that you’d struggle to unlock:
- Respond rapidly to changing customer requirements – a powerful ability that keeps you ahead of the competition
- Smaller changes typically reduce blast radius – an oversimplification but generally true that smaller changes are less impactful, and easier to diagnose if something does go wrong after a deployment
- Improved team engagement – teams who work in a continuous delivery environment report improved engagement and lower burnout (1) (2) citing more influence on decisions that impact their job, improved feeling of being trusted and having a strong sense of purpose.
For many businesses releasing code at this rate is a pipe dream, but there is a scenario when every business adopts continuous delivery practices for a brief moment: priority 1 incidents.
Spontaneous Continuous Delivery

When a priority 1 (P1) incident hits, organisations usually adopt all the practices that enable continuous delivery:
- The incident’s existence and impacts are communicated broadly
- The most knowledgeable people on the affected system congregate
- The group swarms around the task of diagnosing the problem
- The group rapidly discusses solutions to mitigate the incident
- The solution which best balances mitigating effects and time-to-deliver is typically chosen
- The solution is implemented by a small number of individuals, usually two people pairing.
- The boundary of the change is identified and tested
- The change is promoted through whichever environments / test suites need to pass to get changes into production
- The change is pushed to production
- Rapturous applause
The painful irony is that this could easily be your organisation’s Software Delivery Life Cycle today, but with one glaring difference – I’d wager all those people above work on different teams, probably in different departments.
“Team”
The meaning of Team is subjective and highly contextual but after more than 20 years in commercial IT the best definition I’ve found is:
“Everyone necessary to deliver an increment of product”
Mike Cottmeyer, CEO of Leading Agile
Is that what “Team” means in your organisation?
Think about that virtual team that formed when something went wrong.
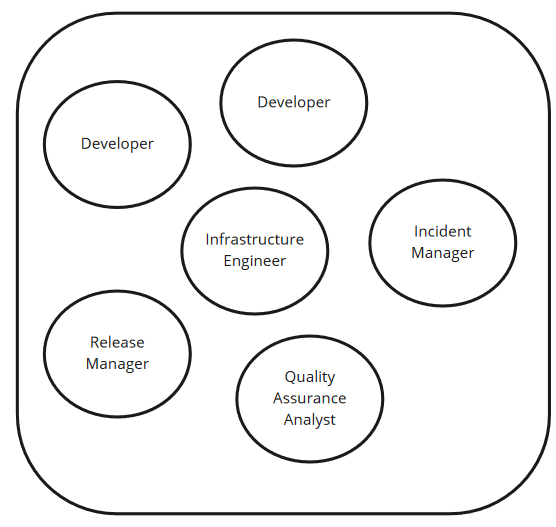
With the exception of the Incident Manager, the team that spontaneously forms, is empowered to make decisions and can successfully deliver a mitigation to a P1 incident entirely autonomously is a strong guide towards the shape of the team you need to achieve continuous delivery.
Naturally, instead of an incident triggering changes, you’d have customer requirements coming into the team, and instead of an Incident Manager you’d have a Product Owner or a Project Manager.
Some incidents require database experts and, as illustrated above, infrastructure engineers. These people probably don’t need to be dedicated to a single team but can span multiple teams. Organisations need to be cognisant of the risks of two incidents happening simultaneously which could introduce contention for these resources. Each organisation is different but consider 2 infrastructure engineers per 3 teams as a starting point. A 5:1 ratio on teams to DBAs is probably enough, but depends on the complexity of your data models and architecture.
In Summary
If you’re interested in shifting to Continous Delivery:
- Create a priority 1 incident
- Find out who is resolving the issue
- Draw a circle around them and call them a team
- (Don’t forget to swap out the incident manager for a PO/PM)
You’re welcome!