
Photo by Fabrizio Frigeni
This is the second State of the AI Nation in the series. You can read the first here and a lot has been happening since that first article.
Big Tech Covers Their Bases
One of the most visible trends in AI over the last few months is the reaction of entrenched “big tech”, specifically, investing in the most promising and infrastructure-like offerings. Big tech are also spending tons of cash training, integrating and monetising their own large language models (LLMs).
Meta (previously Facebook) launched their Large Language Model Meta AI model, contorted into the “LLaMA” acronym, in February, a couple of months after Chat GPT entered all our lives.
LLaMA version 1 was said to outperform the much larger GPT-3 (175B) at natural language processing tasks despite being much smaller, whilst competing well against Google’s PaLM model.
One aspect of LLaMA which makes it interesting is that it is trained on “publicly available datasets exclusively”. There is a storm coming for AI relating to use of copyrighted materials for training which I will come onto in a moment. However, just because something is “publicly available” doesn’t make it OK to use in deep learning.
In July, Meta launched LLaMA-2 completely free for research and commercial use, which has been tuned to emulate human-like chat capabilities and code generation. Chat capabilities will undoubtedly be useful for small and medium businesses who use Facebook as their shopfront and wish to offer a 24/7/365 chatbot to support their customers.
(Side note: I dislike chatbots and my only interactions with them are usually just trying to find the trigger-word/phrase that will let me speak to a real person).
Microsoft aren’t resting on their laurels either. After announcing their $13bn investment in Open AI in January 2023, Satya Nadella climbed into bed with The Zuck offering Microsoft’s cloud computing capabilities to Meta. From this union LLaMA-2, mentioned above, was born.
Microsoft also announced Microsoft 365 Copilot, integrating LLM capabilities into their enterprise productivity suite. I’m pretty sure AI will end up being Augmented Intelligence rather than Artificial Intelligence, so I’m supportive of these co-pilot style features, even if it brings back Clippy PTSD.

I’ve been quite scathing about Microsoft recently and I still haven’t been won round by Redmond. Their previous AI attempts have been depressingly bad.
I have personally been burned by “Viva”, M365’s supposed “AI-powered” insights feature, which I’ve found to be completely useless or worse – on several occasions suggesting the wrong pre-read for a meeting, costing me both my time and my credibility.
Even Microsoft voluntarily paused the Briefing emails from Viva, presumably because so many people had opted out of them. Microsoft’s user
Microsoft are world-class at building infrastructure. Microsoft SQL is amazing and that is a hill I am happy to die on, .NET is incredible despite it mutating towards being a tower of babel, and despite some shockingly severe security issues, Azure is still my first choice cloud.
However, they are TERRIBLE at building applications and seemingly don’t understand web-first design patterns. Microsoft Teams is shockingly poor and very unstable and revenue stalwart Office/M365 is really showing its age.
I mean, come on, it’s 2023 and I can’t put an ampersand in an online Word doc filename because behind the scenes it’s Sharepoint which still uses file extensions to denote file types rather than file metadata???!?! This is obscene and I believe is the perfect demonstration of the lack of innovation at the heart of Microsoft.
Satya Nadella has instead shifted strategy to buying-in innovation, and for some reason the markets are absolutely loving this, with the stock price rising 50% in the last 12 months. It is a shame to see one of the most influential innovation leaders from my formative years become so uninspiring today.
I seriously worry that Microsoft are just bolting on new shiny things without tackling some of these fundamental problems in their products.
Sigh, rant over. (Disclosure: I am a Microsoft shareholder)
Google are also – unsurprisingly – investing heavily in AI, both internally and buying shares of up-and-coming AI businesses.
Google’s PaLM LLM was announced in April 2022, 7 months before Chat GPT was revealed to the world, and opened up to the public via an API in March 2023.
In September 2023, just a couple of weeks ago as I write this, Google announced PaLM 2, the next iteration of their LLM. PaLM 2 has dramatically improved support for multilinguality including idioms and riddles. Google claims PaLM can pass advanced language proficiency exams at “Mastery” level.
PaLM 2 also demonstrates better “reasoning” capabilities, showing better logic skills and mathematics which has sometimes, allegedly, managed to confuse GPT-4:
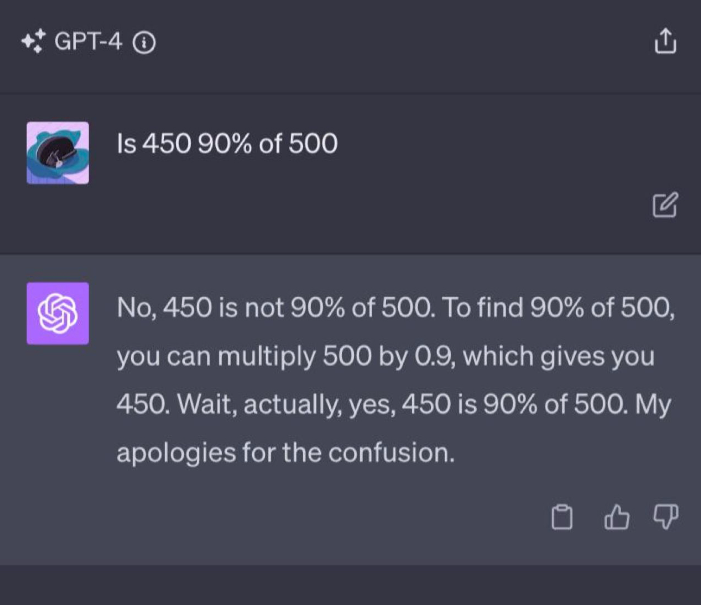
And PaLM 2 also improves on code generation features, adding support for Prolog, Fortran and Verilog.
Just last week, Google started handing out demos of their GPT-4 rival, Gemini which was announced at I/O.
Gemini is multi-modal, meaning it supports text generation, audio, image generation
But as I’ve mentioned before, Google’s unique advantage is they know more about us than anyone in our lives. From search they know your interests, your celeb crushes, your medical problems, your sexual orientation, your pregnancy status, your political leanings, if you’re thinking of having an abortion, if you’re taking illegal substances and your state of mind. GMail and Google Workspace know who and how you communicate with – across both your personal and your work lives.
Google’s Next conference at the end of August 2023 showed how Google continues to embed AI seamlessly into their web-native products and services. For example, their Search Generative Experience – SGE – will shortly include the new “Website Summariser” feature coming to the Chrome browser:
The beauty of features like this is that they don’t “feel” like AI, it almost feels like it’s an excerpt or summary from the website itself – part of the experience. And I’m sure there will be proposals to update the HTML5 specification to help website owners nudge SGE AI to the right summary coming soon.
Profit-averse, internet book-store, Amazon, are also pouring cash into AI.
This week they announced a $4bn investment into Anthropic AI, an AI safety and research company founded by an Open AI alumnus whose objective is to make AI more reliable and understandable. Amazon have said that part of the aim of the investment is to build custom silicon to power AWS’s AI workloads with Anthropic’s capabilities and safety controls built in.
This vertical integration will allow AWS to differentiate its offering from other cloud vendors using commodity components. The expertise at Anthropic will also help AWS develop safer AI models and enhance their thought leadership around policy in this space.
Anthropic have previously attracted investment from Google, Salesforce Ventures, Zoom Ventures and others during their C-round of funding.
There’s a twist in the tale about Anthropic, however, as bankrupt crypto exchange FTX had a half-billion stake the business. This may be good news for FTX creditors. The BBC broadcast a documentary about FTX this week too, bringing names like Anthropic into the mainstream for British viewers:
Speaking of Models…
Models, Models, Everywhere
We’ve seen a proliferation of pre-trained models become available from big (and becoming-big) tech but you don’t have to be a Silicon Valley decacorn to build useful AI models, there is also a growing ecosystem of open-source and license-free models.
The main player in the open model world is Hugging Face. Despite the silly name it is a treasure trove of free-to-use models including specialist models from Microsoft and image-generation experts Stability AI.
My recent article showing how to go from zero to AI-powered sentiment analysis in only 4 lines of code relied on Hugging Face behind the scenes. If you’re new to AI and don’t know where to begin, give that a read:
Hugging Face is funded by Sequoia Capital, Google, Amazon, nVidia, IBM, Qualcomm, AMD and Intel, and in February 2023 announced a partnership with AWS to help build their custom silicon and integrate Hugging Face models directly into AWS services.
What About Deep Unlearning?
Now we’re getting to the real meat of this article and the brewing storm around training AI models.
There are two main issues in play:
- Use of copyrighted materials in the training of an LLM
- Inclusion of personally identifiable information (PII) in an LLM
UN-learning this information will be extremely tricky, as it becomes dispersed in the model’s internals and weightings.
Let’s start with Copyright.
As mentioned above, LLaMA states that it was only trained on ‘publicly accesible’ data sets but that doesn’t say anything about copyrighted material. Nobody outside Open AI knows what is behind the models powering ChatGPT and similarly for PaLM and Google (who have an index of the entire WWW in their databases).
Asking ChatGPT to rewrite the ending of Dreamworks Animation’s Shrek to be an unhappy ending quickly returns a fairly credible alternative plot:
As Shrek and Fiona stand at the edge of the cliff, ready to share True Love’s Kiss and break the curse that has kept Fiona trapped in her ogre form, a sudden rumble shakes the ground beneath them. The sky darkens, and a menacing storm cloud forms overhead.
Chat GPT Alternative Ending to Shrek
Lord Farquaad, who had miraculously survived being eaten by the dragon earlier in the film, reappears in a new, more powerful form. He has made a dark pact with mysterious forces to gain supernatural abilities. Farquaad, now a malevolent sorcerer, swoops down from the sky with a sinister grin.
With a wave of his hand, Farquaad dispels the True Love’s Kiss enchantment. Fiona remains an ogre, and her love for Shrek cannot break the curse. Shrek and Fiona watch in horror as Farquaad reveals his sinister plan to take control of the kingdom of Duloc and enslave all fairy tale creatures.
The fairy tale creatures who had found refuge in Shrek’s swamp are rounded up and imprisoned, and Shrek and Fiona are left powerless to stop Farquaad’s reign of terror. The film ends on a somber note, with Shrek and Fiona realizing that their love alone may not be enough to overcome the darkness that has descended upon their world.
This alternate ending leaves the story with a sense of uncertainty and a looming threat, emphasizing the idea that sometimes, even the strongest bonds of love cannot conquer the forces of evil.
This, at least, means Chat GPT has been trained on the Shrek script, if not the movies themselves. This is clearly copyrighted material.
With Open AI now on the verge of becoming a $100bn company, content publishers and copyright owners are starting to ask if they deserve a cut of that massive pie. (This is the CORRECT question to be asking).
The storm brewing is a potential class-action legal suit against the major AI players to claw back money owned for breach of copyright. I expect we’ll soon see Disney, Warner Bros and Dreamworks joining forces in a test case that could shape AI policy for decades to come.
To their credit, the US government have been quite responsive to the challenge and the US Copyright Office began looking into copyright law issues raised by AI in early 2023. We’ll learn more in their published notes which are due out on October 18th.
The next issue is Personally Identifiable Information (PII).
PII is a very broad term, especially when defined in the GDPR, and includes data which is pseudonymised and/or reversibly encrypted.
It is conceivable that whilst being trained on the public datasets, the AI models absorbed PII from certain individuals.
One solution is to redact the information on output. There are several redaction APIs available today:
For copyrighted materials, it’s going to be very hard without accurately tracing each piece of knowledge back to source. All it would take is for two websites to publish similar articles for that to go out the window.
Opening up the training mechanism for LLMs is one way of tackling this, with publishers opting-in to their data being trawled (for a price!).
What’s Next in AI?
The next big thing is not going to be one-size-fits-all models such as GPT-4, it will be smaller models that can be combined and, most interestingly, highly-personalised models built just for you.
I believe Google is hinting at this with the name of their next model: “Gemini”.
I have worked with “digital twins” before, although in the construction industry.
I strongly believe the next iteration of AI will be small models trained on your own data, your emails, your WhatsApps, etc. These won’t be centralised personal assistants like Siri or Alexa, instead they will run on the edge, on your devices, and they will work offline.
Instead of a generic “It will take you 40 minutes to drive home” message appearing on your phone when you’re leaving the office, your own personal AI will already know your fridge doesn’t have any milk in it because it’s communicated with your personalised AI smart-fridge and knows you’ll need to detour to a shop.
“You need milk. Tesco is on your way home, traffic looks light, and their milk is 20p cheaper than Sainsburys, plus you will earn Clubcard points” is much more actionable for you.
“Gemini” suggests digital twinning, although seems much more centralised than I expect it will become. Google can vertically integrate digital twins into Android software and their Pixel smartphones.
The real question is, where is Apple? And despite Apple’s notorious secrecy, the answer seems to be…. nowhere.
(Disclosure: Apple investor)
I mentioned in my last State of the AI Nation that Apple has a distinct advantage when it comes to deep learning at the edge and, despite plenty of news articles and bluster, worryingly little has actually appeared. Even autocorrect (or autocorrupt as my friends and I refer to it) is still absolutely terrible.
But wait, a new player has entered the smartphone ring. Well, a handful of old players with a new idea.
Open AI’s CEO Sam Altman, ex-Apple design chief Jonny Ive, and Softbank CEO Masayoshi Son have combined forces to build “the iPhone of Artificial Intelligence”.
Interestingly here, Softbank still owns 90% of the shares in UK-born chip designer, ARM, which IPO’d earlier this month, so the trio have access to significant expertise in custom silicon that could help them differentiate. Ive’s eye for design is unmatched, and Altman knows generative AI – or at least, how to productise and monetise it – better than anyone in the world right now.
This is definitely one group to watch. What it would mean to Apple if they launched an Ive-designed, AI-centric smartphone hardly bears thinking about.
Til next time!



